Machine Learning Algorithms
Logistic Regression
Logistic regression is used for binary classification problems...

from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
Linear Regression
Linear Regression predicts a continuous output based on input features...
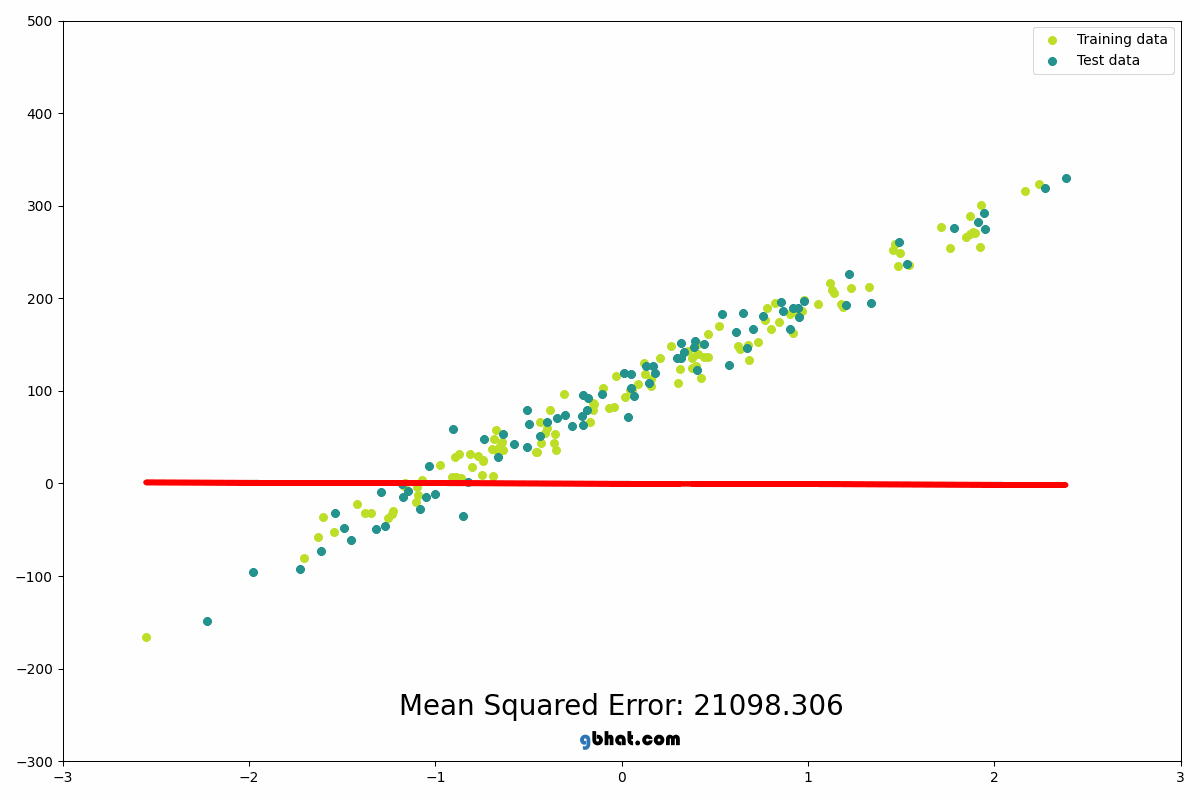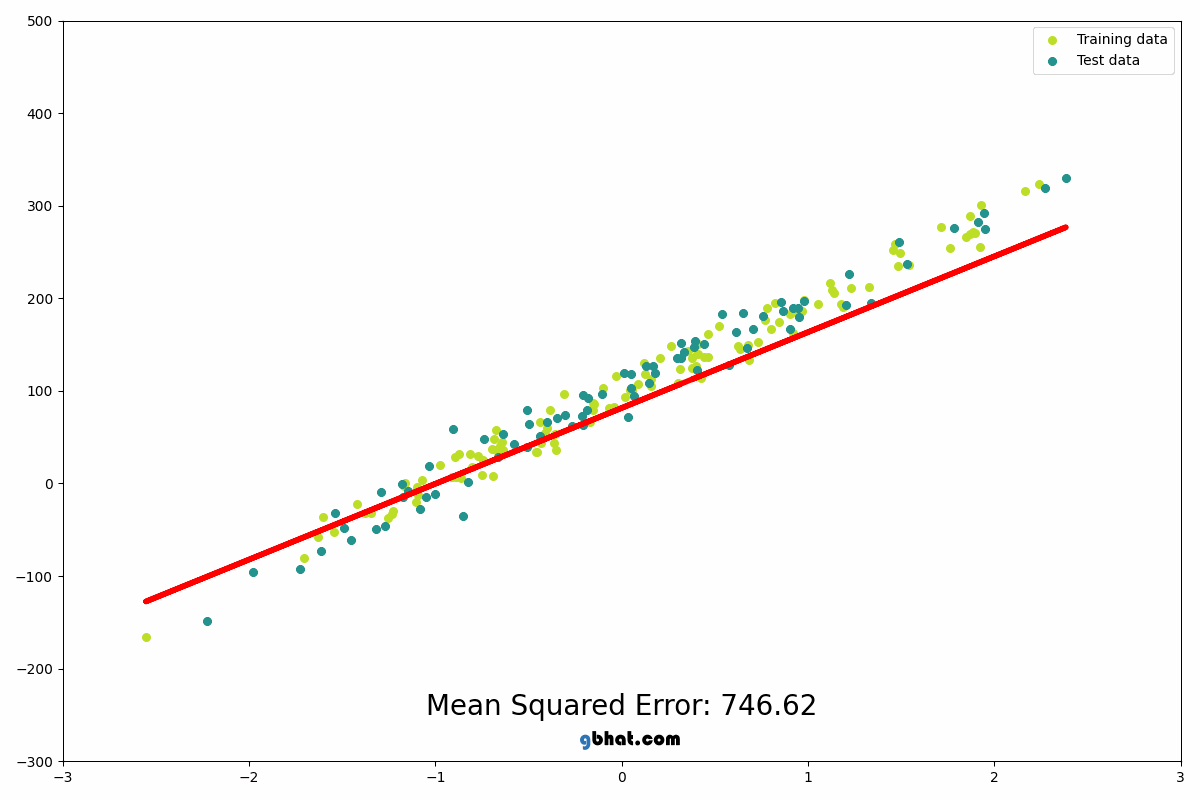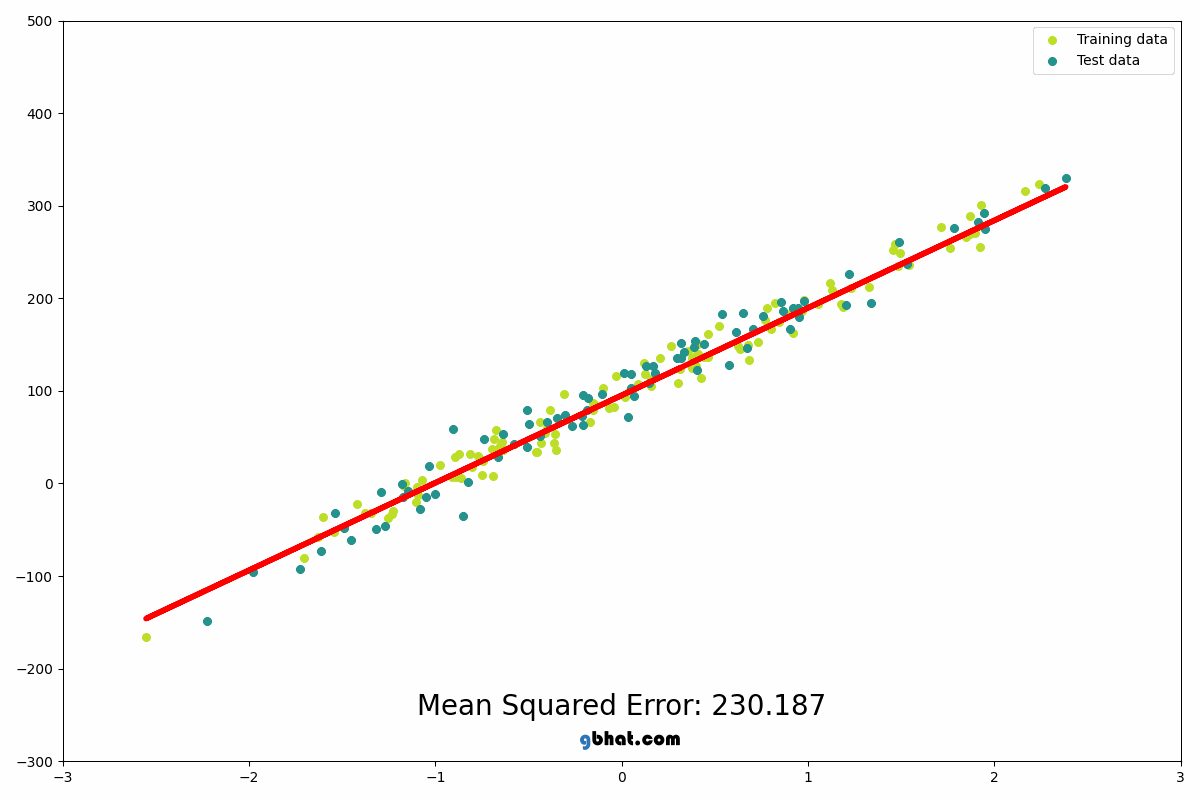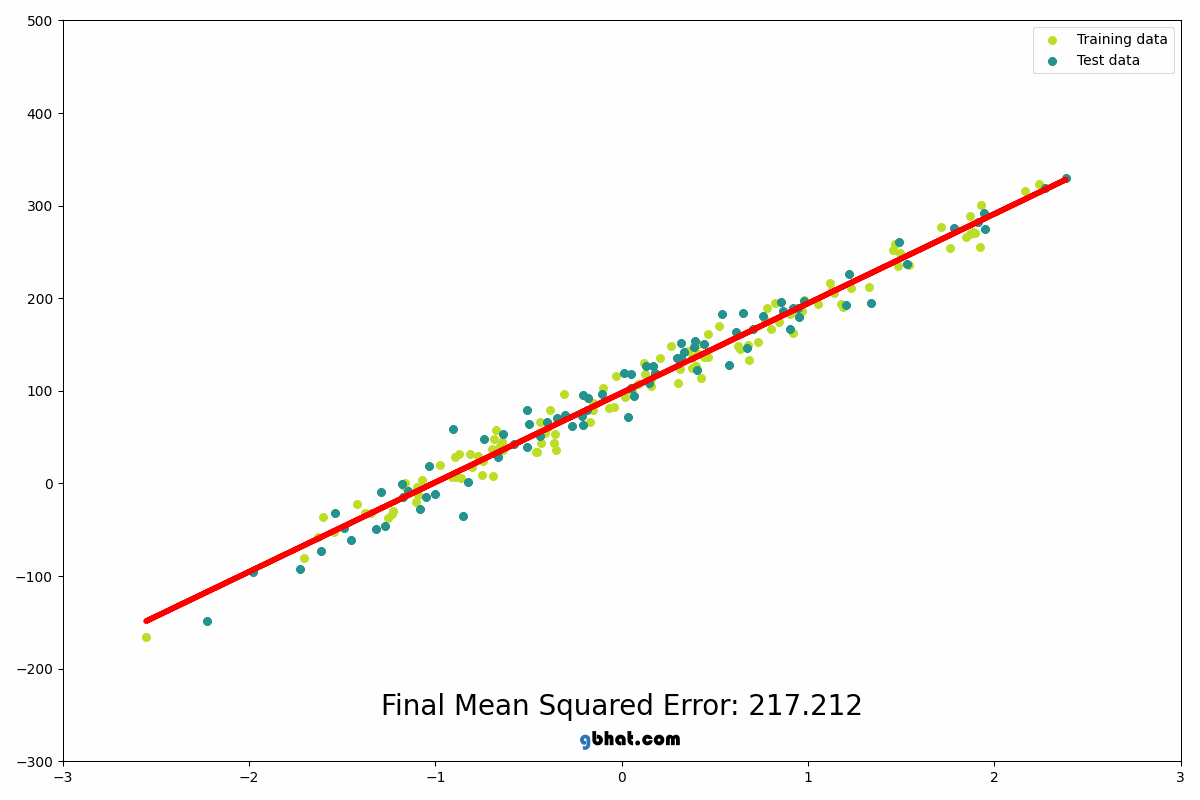
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test) print(predictions)
Polynomial Regression
Polynomial Regression extends Linear Regression by fitting a polynomial curve...
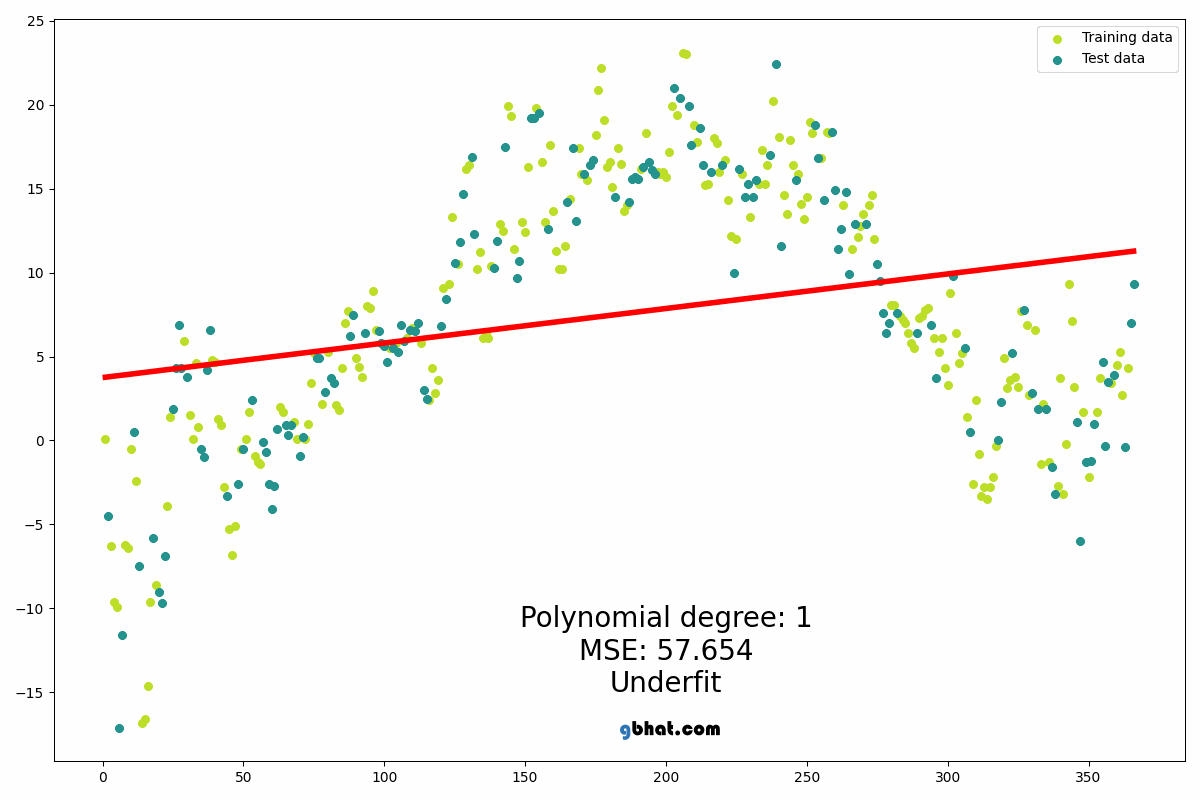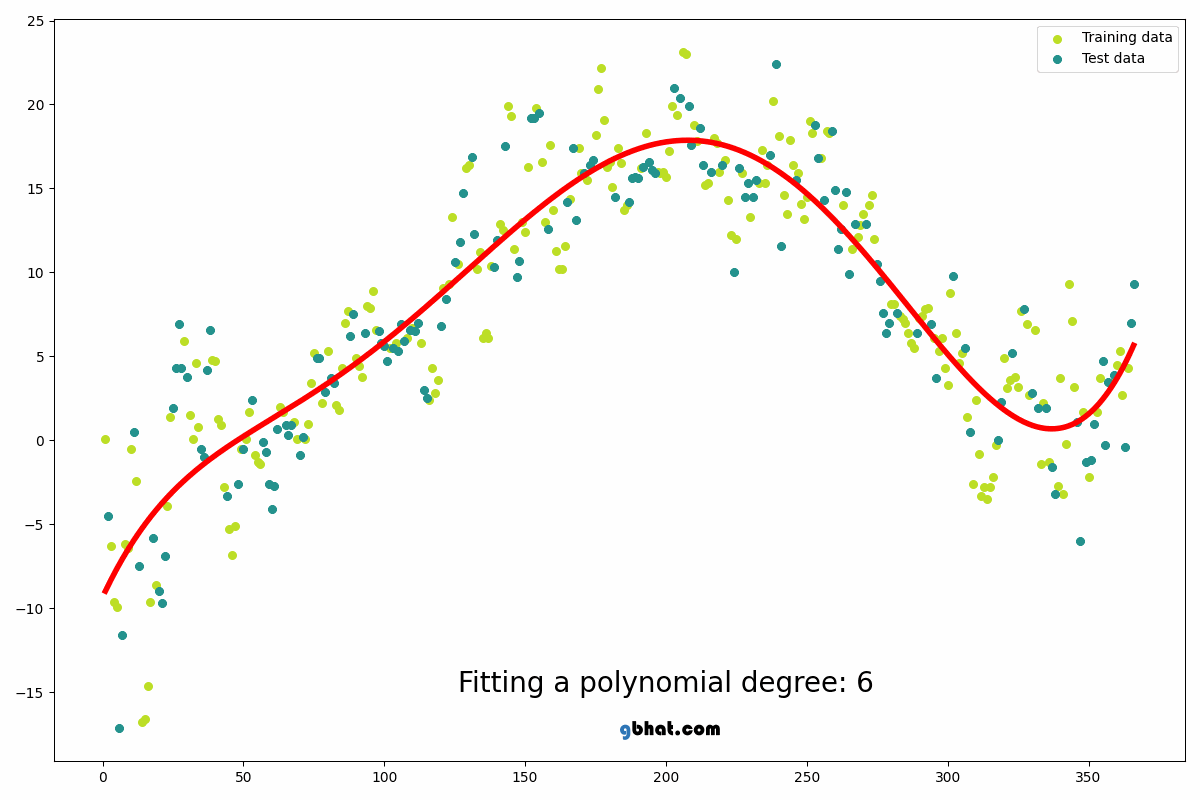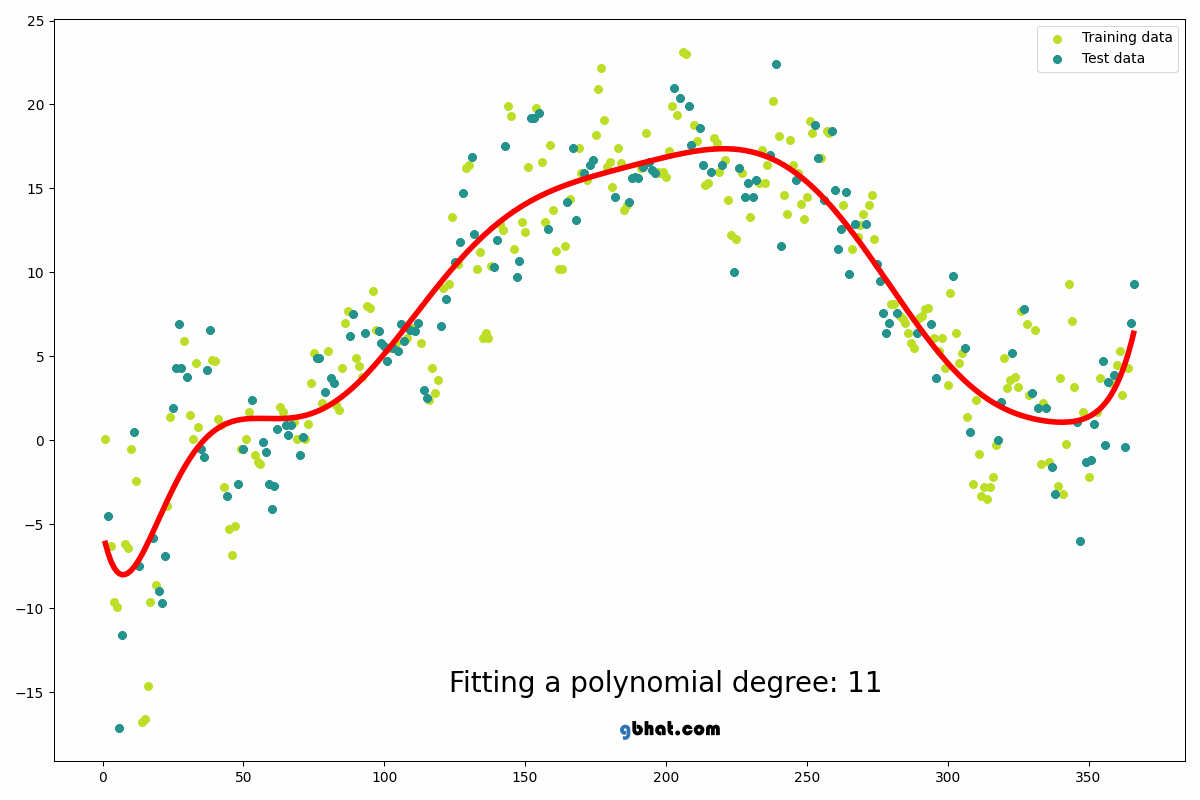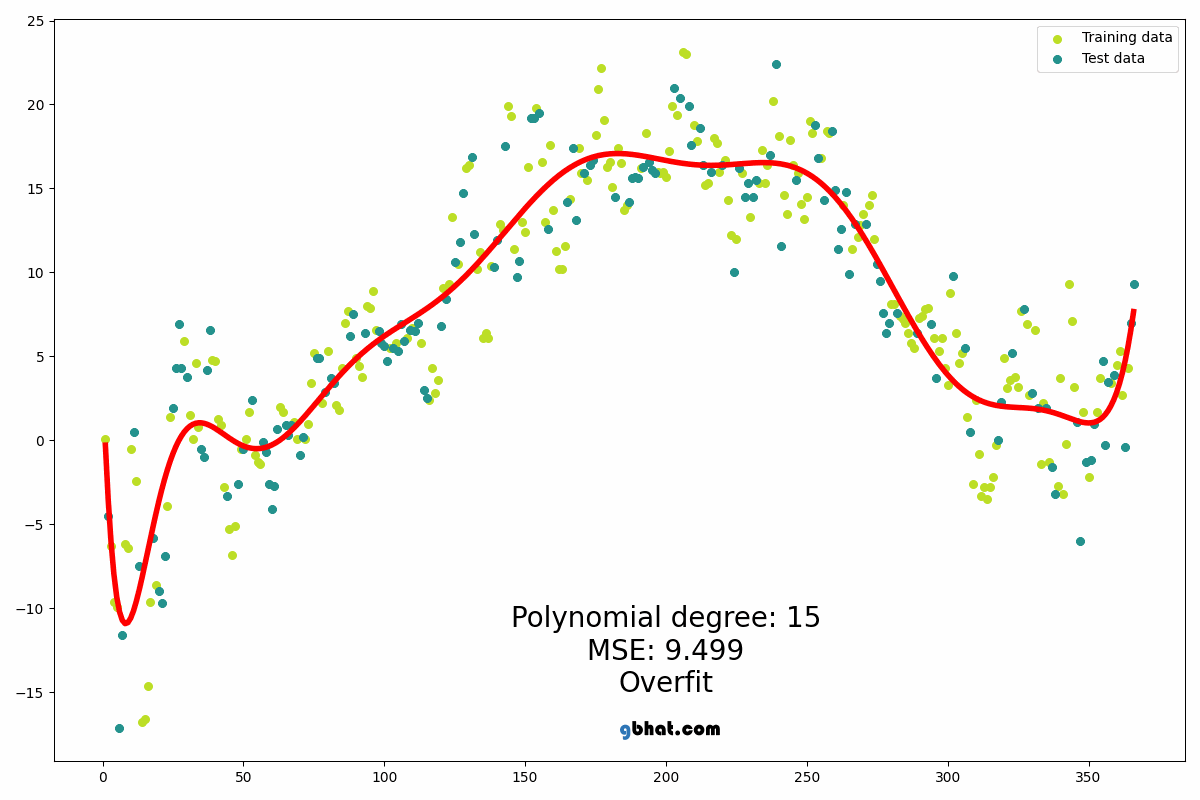
from sklearn.preprocessing import PolynomialFeatures from sklearn.linear_model import LinearRegression poly = PolynomialFeatures(degree=2) X_poly = poly.fit_transform(X_train) model = LinearRegression() model.fit(X_poly, y_train)
Decision Tree
Decision Tree is a non-parametric supervised learning method used for classification and regression...
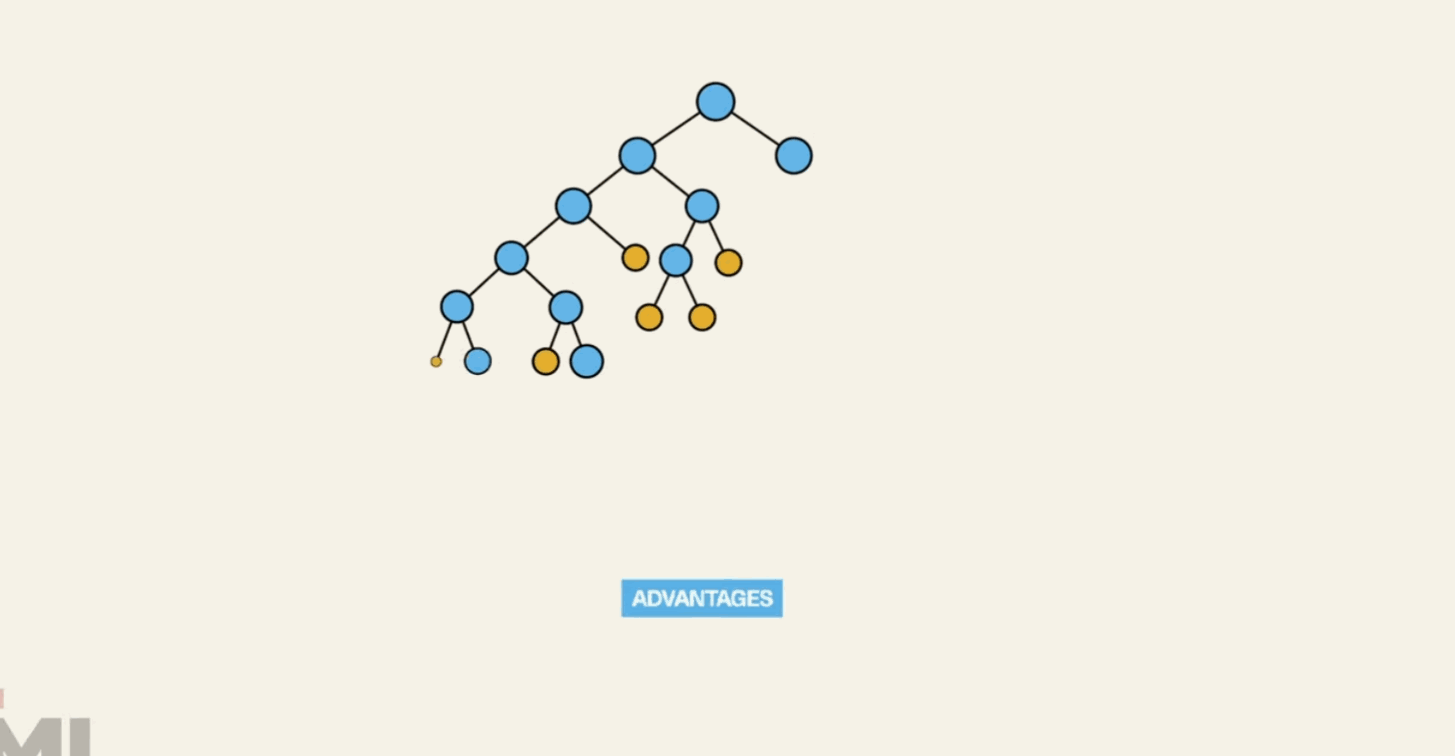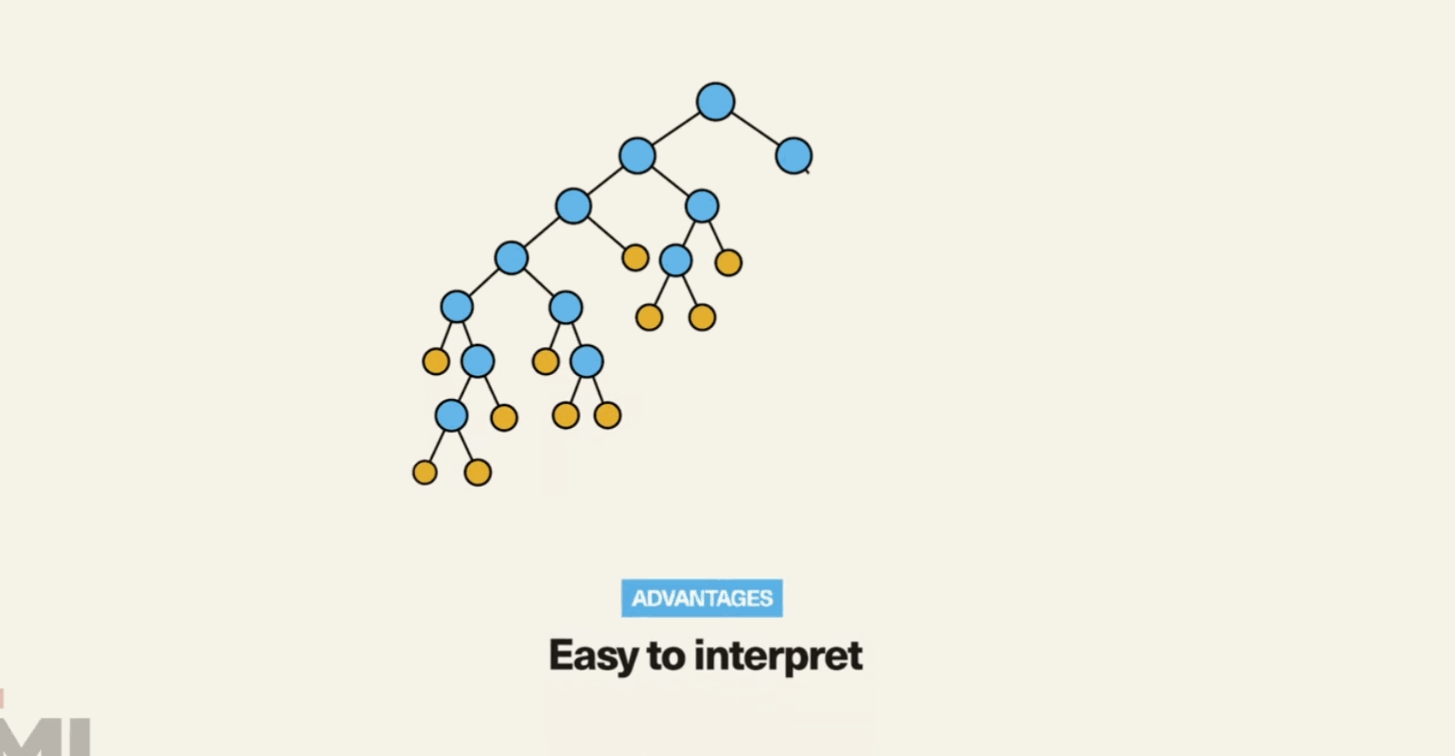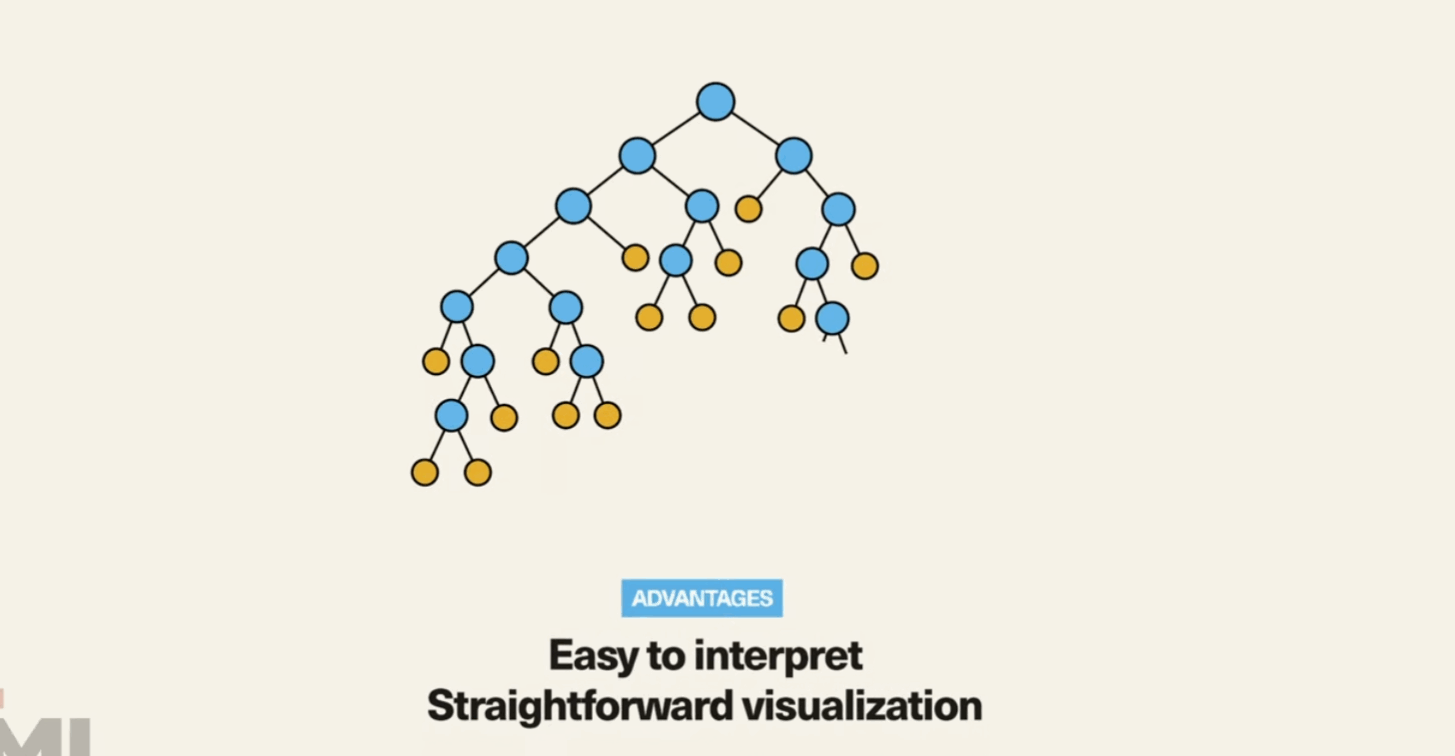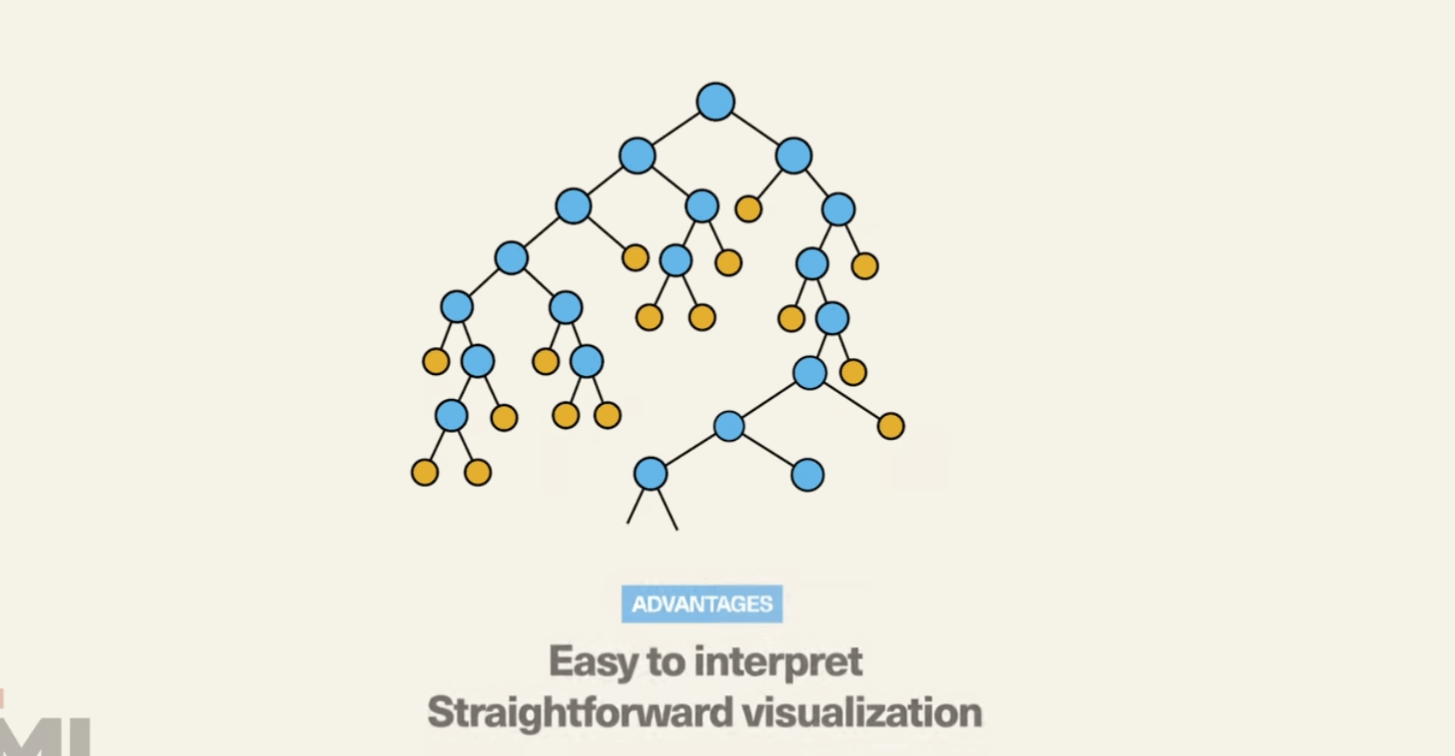
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
Random Forest
Random Forest is an ensemble learning method that combines multiple decision trees...

from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
Gradient Boosting
Gradient Boosting is an ensemble technique that builds models in a stage-wise fashion...
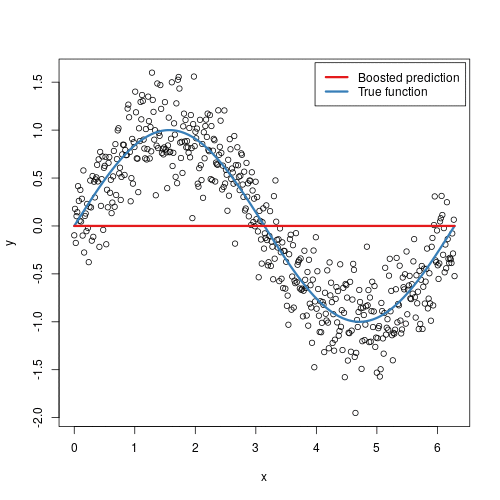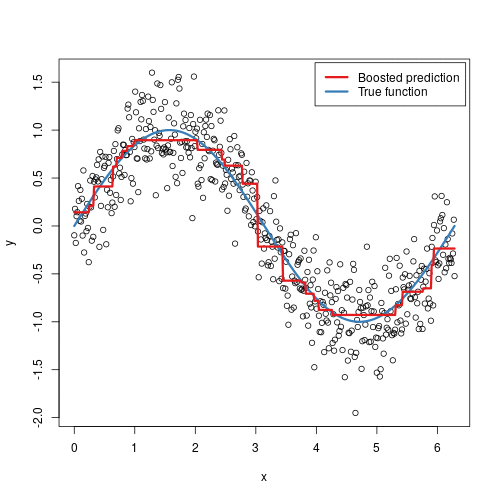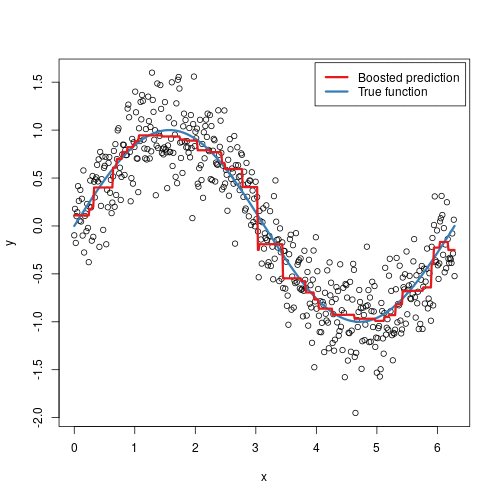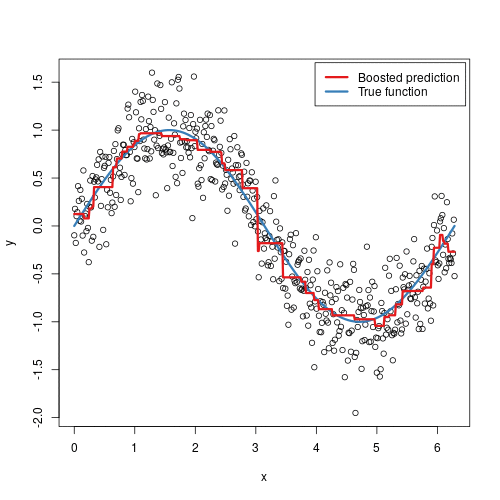
from sklearn.ensemble import GradientBoostingClassifier model = GradientBoostingClassifier() model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
k-Nearest Neighbors (k-NN)
k-NN is a simple, instance-based learning algorithm used for classification and regression...

from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier(n_neighbors=3) model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
Support Vector Machine (SVM)
SVM is a supervised learning algorithm used for classification and regression...
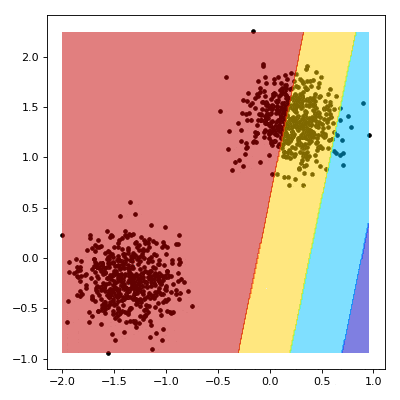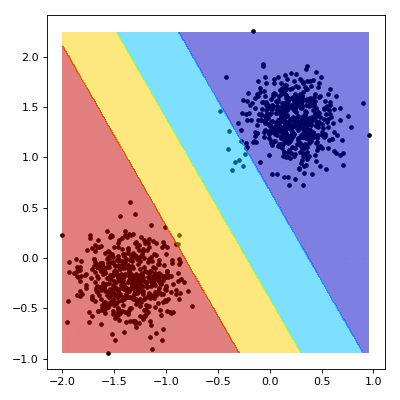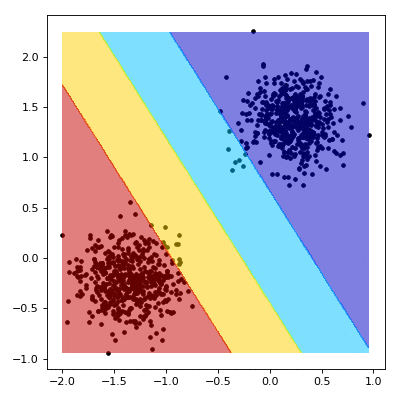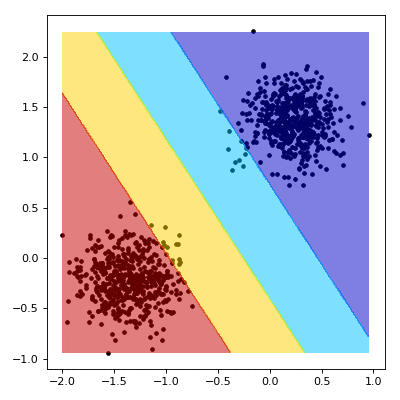
from sklearn.svm import SVC model = SVC(kernel='linear') model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
Ridge, Lasso, and ElasticNet
These are regularization techniques used to prevent overfitting in regression models.
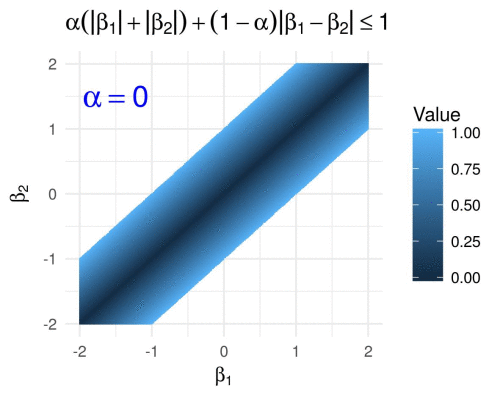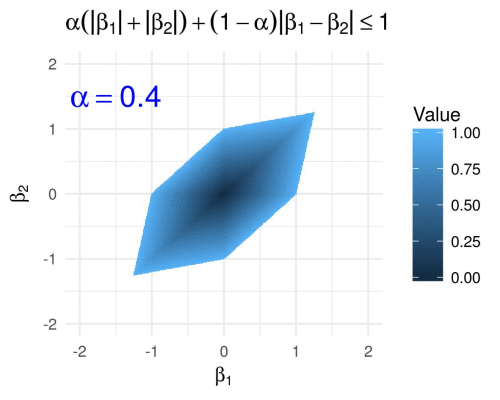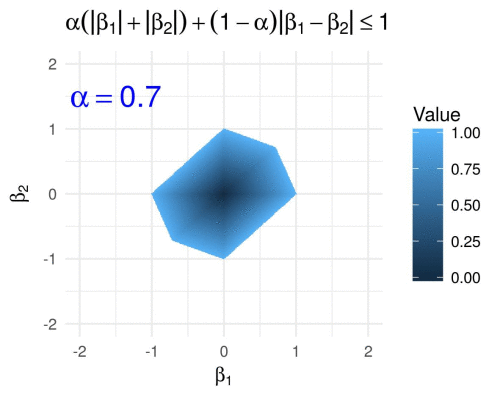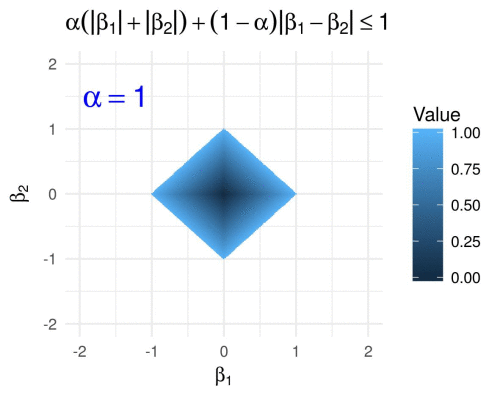
from sklearn.linear_model import Ridge, Lasso, ElasticNet # Ridge Regression ridge = Ridge(alpha=1.0) ridge.fit(X_train, y_train) # Lasso Regression lasso = Lasso(alpha=0.1) lasso.fit(X_train, y_train) # ElasticNet elasticnet = ElasticNet(alpha=0.1, l1_ratio=0.5) elasticnet.fit(X_train, y_train)
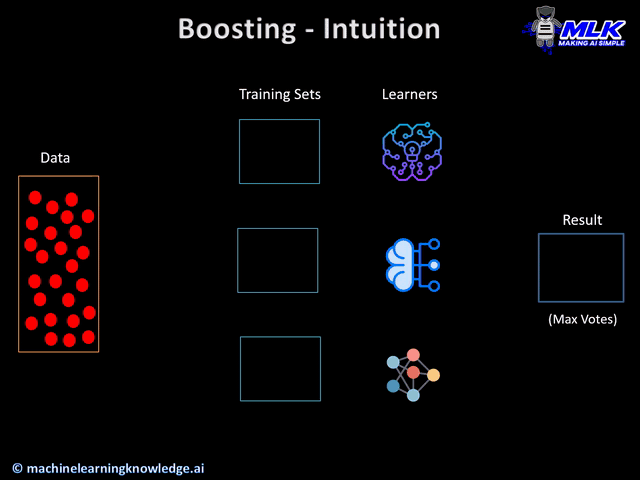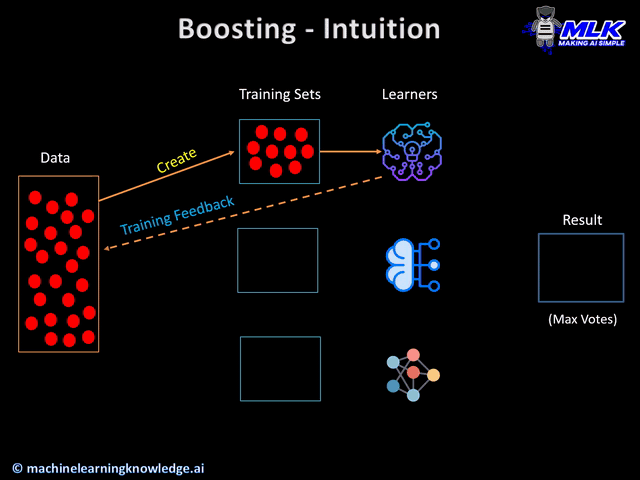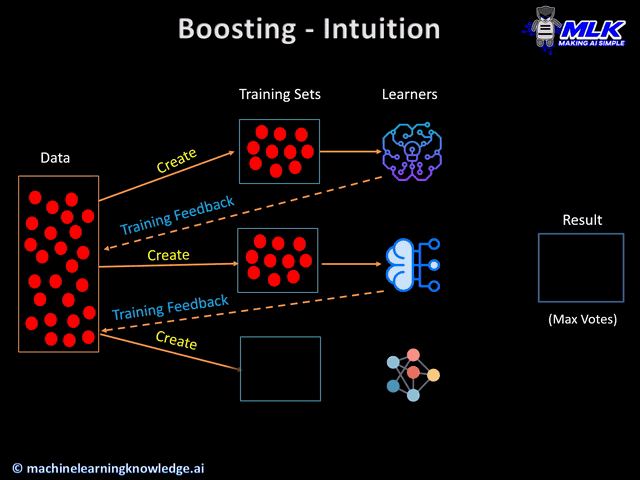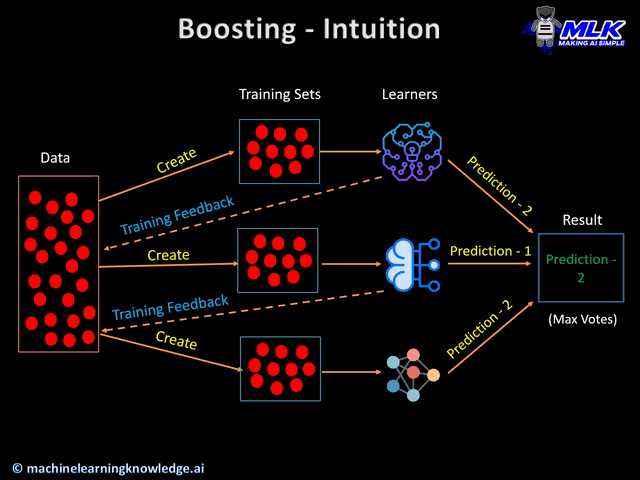
XGBoost
XGBoost is an optimized gradient boosting framework used for supervised learning problems.
from xgboost import XGBClassifier model = XGBClassifier() model.fit(X_train, y_train) predictions = model.predict(X_test) accuracy = model.score(X_test, y_test) print(accuracy)
Gradient Descent and its Variants
Gradient Descent is an optimization algorithm used to minimize the cost function in machine learning.
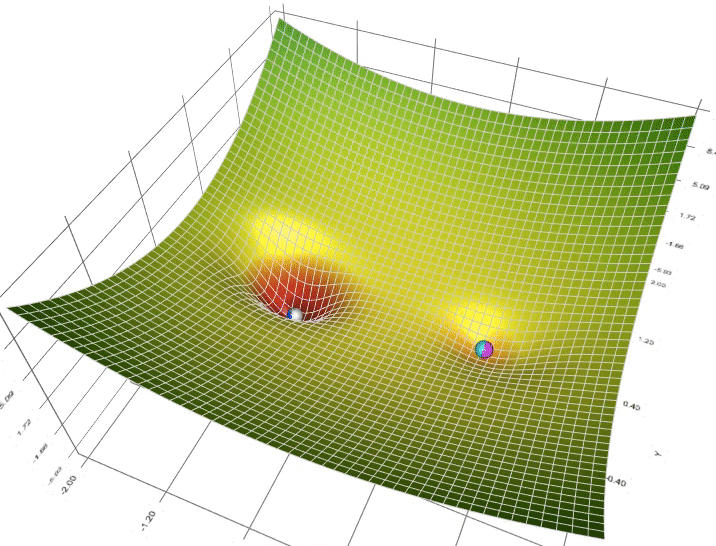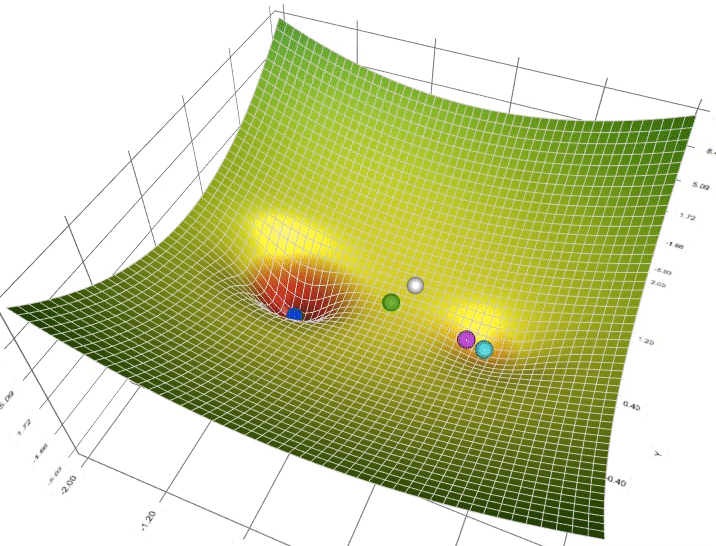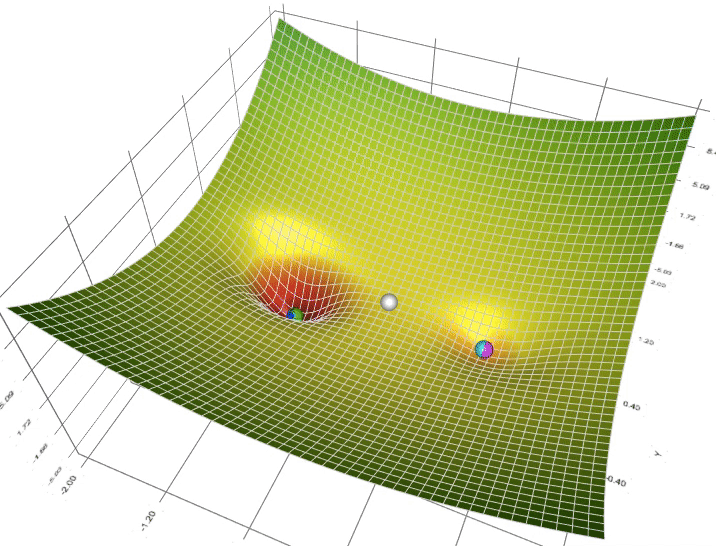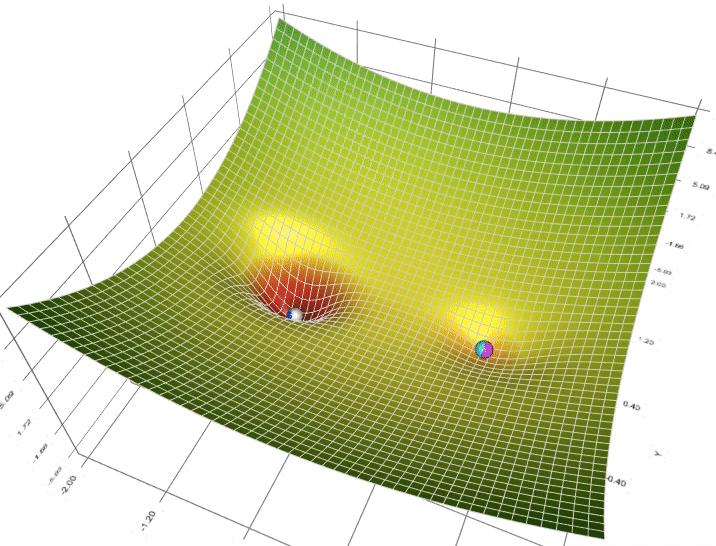
# Gradient Descent Variants
# Batch Gradient Descent
theta = np.zeros(X_train.shape[1])
for _ in range(epochs):
gradients = -2 * X_train.T.dot(y_train - X_train.dot(theta)) / len(y_train)
theta -= learning_rate * gradients
# Stochastic Gradient Descent
for i in range(len(X_train)):
gradients = -2 * X_train[i].T * (y_train[i] - X_train[i].dot(theta))
theta -= learning_rate * gradients
# Mini-Batch Gradient Descent
batch_size = 32
for i in range(0, len(X_train), batch_size):
X_batch = X_train[i:i+batch_size]
y_batch = y_train[i:i+batch_size]
gradients = -2 * X_batch.T.dot(y_batch - X_batch.dot(theta)) / batch_size
theta -= learning_rate * gradients